Research section
Hearing systems

Head of Section: Torsten Dau
Our research is concerned with auditory signal processing and perception, speech communication, audiology, objective measures of the auditory function, computational models of hearing, hearing instrument signal processing and multi-sensory perception.
Our goal is to increase our understanding of the human auditory system and to provide insights that are useful for technical and clinical applications, such as speech recognition systems, hearing aids, cochlear implants as well as hearing diagnostics tools.
Part of our research is carried out at the Centre for Applied Hearing Research (CAHR) in collaboration with the Danish hearing aid industry. More basic hearing research on auditory cognitive neuroscience and computational modeling is conducted in our Centre of Excellence for Hearing and Speech Sciences (CHeSS), in collaboration with the Danish Research Centre for Magnetic Resonance (DRCMR). While our clinically oriented research is conducted at the Copenhagen Hearing and Balance Centre (CHBC) located at Rigshospitalet, which enables us to closely collaborate with the clinical scientists and audiologists.
Our section consists of six research groups with different focus areas. The Auditory Cognitive Neuroscience group (Jens Hjortkjær) studies how the auditory brain represents and computes natural sounds like speech. The Auditory Physics group (Bastian Epp) investigates how acoustic information is processed and represented along the auditory pathway. The Clinical and Technical Audiology group (Abigail Anne Kressner) is focused on cross-disciplinary research that combines knowledge from engineers and clinicians to increase the understanding of hearing impairment and how technology can be used to treat it. The Computational Auditory Modeling group (Torsten Dau) studies how the auditory system codes and represents sound in everyday acoustic environments. The Music and Cochlear Implants group (Jeremy Marozeau) aims to help restore music perception in cochlear implant patients by using several different approaches such as neuroscience, music cognition, auditory modeling, and signal processing. Finally, the Speech Signal Processing group (Tobias May) use digital signal processing and machine learning to analyze and process sound. You can read more about each group and our exciting research projects in the menu on the left hand side.
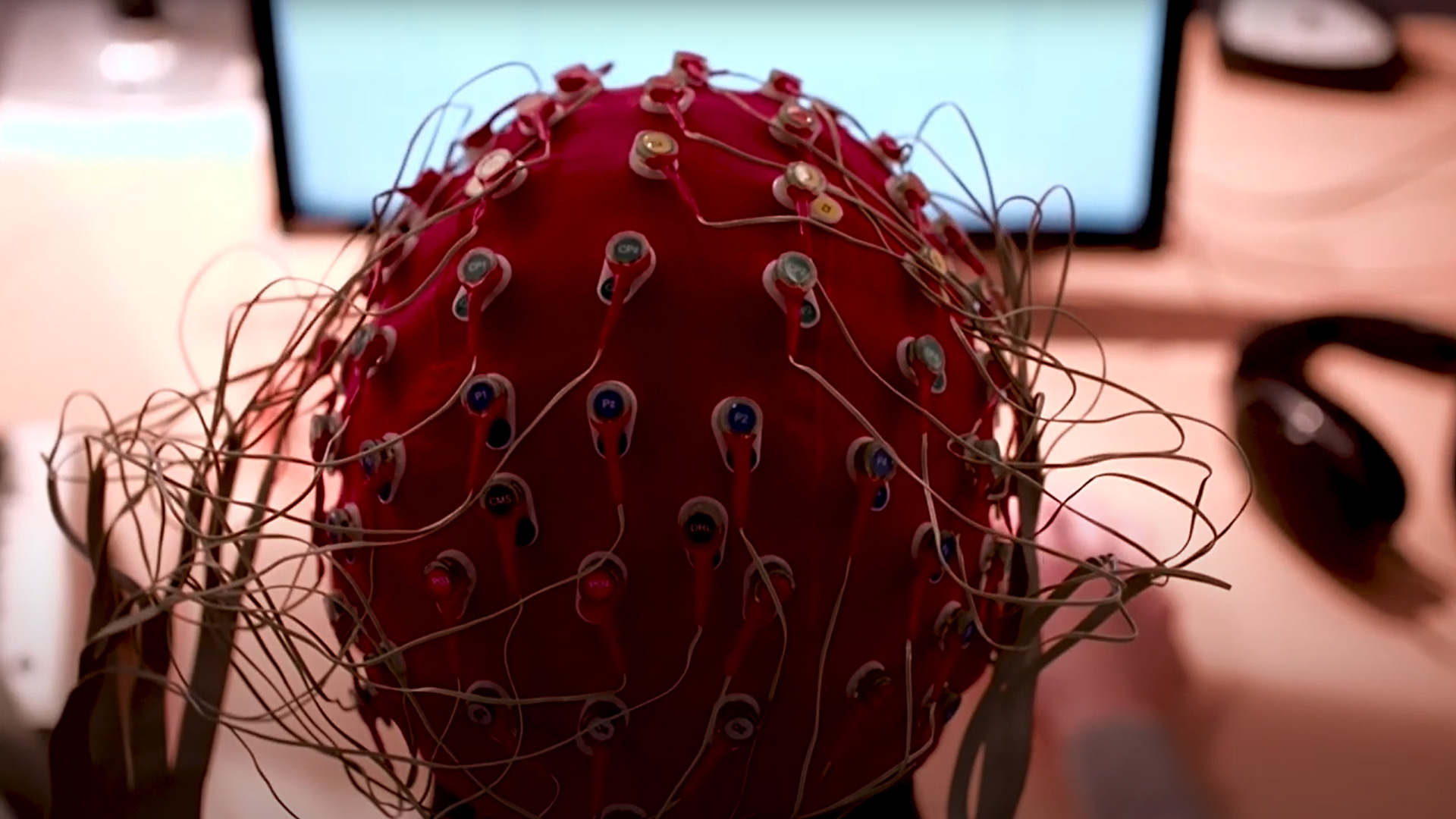
We have exciting lab facilities, including our Audiovisual Immersion Lab (AVIL), a physiology lab, a psychoacoustics lab, and two communication Labs. The tools and facilities used for research and teaching include acoustically and electrically shielded testing booths, anechoic chambers, EEG and functional near-infrared spectroscopy (fNIRS) recording systems, an otoacoustic emission recording system, an audiological clinic, a virtual auditory environment, an eye-tracking system and a real-time hearing-aid signal processing research platform.
If you wish to take part in our research as a collaborator, student or test participant, then please don’t hesitate to contact us.









Research Facilities

Physiology lab
An electrophysiology lab with two eletrically and acoustically shielded booths for electroencephalography and otoacoustic emissions measurements

Audiovisual Immersion Lab (AVIL)
AVIL is a virtual environment for hearing research and enables a realistic reproduction of the acoustics of real rooms, and the playback of spatial audio recordings.

Conversation lab
The Conversation Lab is designed for experiments involving multiple participants. In this lab, we recreate real-life conversations in order to investigate how interactive communication behavior shapes our capacity to communicate successfully with each other.

Psychoacoustics Lab
A psycoacoustics lab with four acoustically shielded listening booths used for audiometry, psychoacoustic and speech intelligibility experiments where sound is typically presented through headphones

Communication lab
The communications lab is used to investigate communication between two participants in order to learn how hearing loss or noisy environments effect conversations.

Clinic
An audiological clinic with equipment for audiometry, ear analysis, otoscopic inspection, and hearing aid measurements.
Lily Cassandra Paulick Student Students s193608@student.dtu.dk
Computational modelling of the perceptual consequences of individual hearing loss
Lily investigates the perceptual consequences of hearing loss using a computational modelling framework. While recent modeling studies have been reasonably successful in term of predicting data from normal-hearing listeners, such approaches have failed to accurately predict the consequences of individual hearing loss even when well-known impairment factors have been accounted for in the auditory processing assumed in the model. While certain trends reflecting the ‘average’ behavior in the data of hearing-impaired listener can be reproduced, the large variability observed across listeners cannot yet be accounted for.
The hypothesis of the study is that, based on recent insights from data-driven ‘auditory profiling’ studies, computational modelling enables the prediction of perceptual outcome measures in different sub populations (i.e. different auditory profiles), such that their distinct patterns in the data can be accounted for quantitatively and related to different impairment factors. More realistic simulations of the signal processing in the inner ear, the cochlea, will be integrated in the modelling. Most hearing losses are ‘sensorineural’ and have their origin in the cochlea and sensorineural hearing loss has recently been demonstrated to also induce deficits at later stages of auditory processing in the brainstem and central brain.
Beatriz de Sousa e Meneses Tomás da Costa PhD Student Department of Health Technology bede@dtu.dk
Assessing Hearing Performance of Teenagers with Hearing Aids and Cochlear Implants using Functional Near-Infrared Spectroscopy (fNIRS)
The large variability in hearing outcomes among patients with cochlear implants (CIs) and hearing aids (HAs) has been associated in part to cross-modal reorganization - functional changes in cortical regions following sensory deprivation. There is increasing evidence that visual cross-modal activation in auditory areas may predict speech perception with hearing devices, but its adaptive or maladaptive nature remains unclear. Variations in stimulation type and recording paradigms, time point of assessment, and clinical case history (e.g. duration and cause of auditory deprivation, age at onset of hearing loss, hearing therapy, etc) have affected reported results in literature. In Denmark, the implementation of the 3-year Auditory Verbal Therapy (AVT) program has improved audiological care for children with hearing loss. Through this program, which is based on the assumption of neuroplasticity in the young brain and focuses on auditory rather than visual cues in the training, 84% of participants achieved age-appropriate spoken language skills.
The aim of this study is to investigate whether the observed variability in speech perception outcomes can be partly explained by the cross-modal activation patterns, extending previous findings to this new generation of teenager patients with hearing devices that benefited from AVT, using functional Near-Infrared Spectroscopy (fNIRS). fNIRS-detected neural markers could complement the traditional clinical assessments of hearing device benefit and could further inform optimal rehabilitation strategies.
Colin Quentin Barbier PhD Student Department of Health Technology Mobile: +33674706994 cquba@dtu.dk
Characterizing the effects of compression and reverberation on spatial hearing for cochlear implant users
In normal hearing, localization and spatialization functions rely on both monaural and binaural cues. As very strong compression schemes are used in signal treatment in cochlear implants, it is unclear how these compressions affect the synchronization of sound signals in between ears, and therefore the binaural cues accessible for the user. Furthermore, clinicians traditionally tune cochlear implants independently one ear after another as no binaural fitting guidelines exist to maximize binaural benefits.
In this project we will assess the influence of compressions on binaural cues for bilateral cochlear implant users in realistic environments (more or less reverberant) with the objective to come up with best practice guidelines for clinicians to preserve as much as possible these binaural cues.Sarantos Mantzagriotis Student Students s203135@student.dtu.dk
Investigating novel pulse shapes through computational modeling of the neural-electrode interface and psychophysics experiments
A major limitation in Cochlear Implantation (CI) is the spread of current excitation induced by each electrode, resulting in a reduced efficiency between the electrical pulse and auditory nerve responses. This current spreading mis-activates neuronal populations of the auditory nerve resulting in poor frequency resolution, dynamic range, and distortion of the original acoustical signal. It is hypothesized that currently used rectangular pulses, are far from optimal for maximizing information transmission within the neural-electrode interface.
In addition, a CI’s outcome is highly dependent on a patient’s anatomical characteristics such as cochlear morphology and auditory nerve fiber distribution. Current pre-surgical planning software for CI can reconstruct a patient-specific cochlear morphology based on high-resolution scans in order to identify the most optimal electrode location and depth, that minimizes current spread. However, these frameworks are still underdeveloped to identify most-optimal parameters of a CI stimulation strategy and pulse shapes.
The project aims at improving pitch discrimination and musical perception in CI by optimizing in-silico, pulse shapes and stimulation strategy parameters. Initially, it will investigate this by creating a computational framework that couples phenomenological neuronal models, based on animal experimentation, with 3D cochlear electrical conduction models. The framework will then be extended to investigate collective neuronal behavior based on population models, combining feedback from psycho-acoustical experimentation.
Valeska Slomianka PHD STUDENT vaslo@dtu.dk
Characterizing listener behaviour in complex dynamic scenes
The aim of Valeska's project is to explore and analyze listener behavior in environments with varying degrees of complexity and dynamics. Specifically, listeners will be monitored continuously using various sensors, such as motion and eye trackers, to record body and head-movement trajectories, as well as eye-gaze throughout the experimental tasks. The underlying hypothesis is that difficulties in processing and analyzing a scene will be reflected in the tracked measures and that comparing behavior across different scenes will help pinpoint which aspects of the scenes pose challenges for the listener. This, in turn, will help to differentiate listener behavior and performance depending on the auditory profile that characterize the individual listeners’ hearing loss and as a function of the scene complexity. Furthermore, this grouping and characterization will support the selection of appropriate compensation strategies tailored to the individual listener (i.e., ‘profile aware) and environment (i.e., ‘scene aware’).
Miguel Temboury Gutierrez Postdoc Department of Health Technology mtegu@dtu.dk
Model-based precision diagnostics
Early diagnosis is crucial for timely hearing rehabilitation. At present, clinical diagnosis for hearing loss relies primarily on pure-tone audiometry, which falls short of fully capturing the complexity of cochlear pathophysiology and does not reflect one's ability to listen in noise. On the contrary, brain responses to acoustic stimuli reflect synchronized activity originating from diverse cellular populations, providing a powerful non-invasive tool for directly assessing pathophysiology.
This work aims to systematically simulate auditory evoked brain responses to sound stimuli of varying complexity using a state-of-the-art computational modeling framework. These responses will be measured from the cochlea (via electrocochleography, ECochG) and the brainstem (through clinical subcortical EEG). Responses simulated with healthy cochlear models, and models representing various pathophysiological profiles of cochlear damage, will be employed to train a machine-learning model. This model is intended to identify patterns in AEPs that effectively isolate pathological profiles, yielding robust, relative measures suitable for precision diagnostics.
The knowledge generated in this project has the potential to inspire novel diagnostic paradigms, such as markers for cochlear neural or metabolic degeneration.
Asher Lou Isenberg PhD Student Department of Health Technology alois@dtu.dk
Jonatan Märcher-Rørsted Researcher Department of Health Technology jonmarc@dtu.dk
Correlates of auditory nerve fiber loss
Our ability to communicate in social settings relies heavily on our sense of hearing. Hearing loss can greatly diminish our ability to discriminate between speech and background sounds, and can therefore be detrimental for communication in everyday life. Although diagnosis and treatment of hearing loss has progressed, there are still many aspects hearing loss which are not fully understood. Understanding how specific pathologies in the cochlea develop, and how they affect auditory processing and perception is essential for correct treatment and diagnosis.
Recent research has discovered that the neural connection between the cochlea and the brain (i.e. the auditory nerve) can be damaged, even before a loss of sensitivity emerges. While it is known that this phenomenon is caused by excessive noise exposure and aging, robust diagnostics of such peripheral neural loss are missing. This project investigates potential correlates of auditory nerve fiber loss, and its functional consequence on auditory processing in the periphery, the mid-brain and the auditory cortex using clinical audiology and electrophysiological paradigms.
Mark Saddler Postdoc Department of Health Technology marksa@dtu.dk
Machine learning models of auditory perception
Mark builds computational models of the auditory system by training machine learning systems to perform everyday hearing tasks. The underlying idea is that evolution and development generally drive biological perceptual systems towards optimal performance on tasks that matter for survival. By optimizing machine perceptual systems under similar constraints, it is possible to obtain computational models that “hear” like humans. Mark combines this machine learning approach with detailed models of the ear’s signal processing to investigate how changes in the peripheral auditory system (i.e., hearing loss) underlie changes in perception. By linking specific aspects of the ear’s neural coding to real-world hearing difficulties, this work aims to provide insight into the diversity of individual hearing loss outcomes. Additionally, this work explores model-based strategies for diagnosing and compensating for hearing loss.
Maaike Charlotte Van Eeckhoutte Assistant Professor Department of Health Technology mcvee@dtu.dk
Audiology and Hearing Rehabilitation
On January 6th, Maaike Van Eeckhoutte started as a postdoc in Audiology and Hearing Rehabilitation. It is a new joint position in the Hearing Systems section at the Department of Health Technology at DTU and in the Department of Otorhinolaryngology, Head and Neck Surgery & Audiology at Rigshospitalet. A major goal is to facilitate the translation of research between the technical university and the clinic. The combination of technical and clinical aspects was exactly what attracted her and made her decide to move to Denmark. While having a background in clinical audiology, she has always had a strong interest in translating fundamental sciences into applications for clinical practice. Previously, she was conducting research in audiology and neuroscience during her time as a PhD student at the KU Leuven in Belgium, and translational research at the National Centre for Audiology in Canada, where she did her first postdoc. With this shared position, she sees many possibilities to set up new exciting research focused on helping the patient.
Tobias Dorszewski PhD Student Department of Health Technology tobdor@dtu.dk
Audiovisual deep learning for cognitive hearing technology
Situations involving multiple simultaneous conversations are very common in everyday life. Following speech in such noisy surroundings can be challenging particularly for hearing impaired individuals. My PhD project will hopefully bring us closer to having a wearable computing device that can help in these situations by amplifying speech from the people one wants to listen to. Such a device could benefit from multiple types of sensors, such as microphones, eye-gaze trackers, electroencephalography, or ego-centric video. Additionally, such a system would need a smart way of integrating this information which could be achieved with multi-modal AI-based approaches.
Primarily, I am interested in using ego-centric video and deep learning for determining communication context. Communication context refers to the question “who is part of a conversation?”. It goes beyond instantaneous attention and related aspects such as “who is talking to me”, which are investigated in related works. Identifying communication context requires a new approach that can integrate audio and video from a longer temporal context. As a first step, I will be collecting ego-centric video and audio from multiple people during a communication experiment with multiple conversations happening simultaneously. Then, I will explore ways of analyzing the data with audio-visual deep learning approaches
Supra-threshold hearing characteristics in chronic tinnitus patients
Tinnitus is a challenging disorder which may result from different etiologies and phenotypes and lead to different comorbidities and personal responses. There are currently no standard ways to subtype the different tinnitus forms. As a result, any attempts to investigate tinnitus mechanisms and treatments have been challenged by the fact that the tinnitus population under study is not homogeneous. We suggest that subgrouping tinnitus patients based on a thorough examination of their hearing abilities offers the opportunity to investigate and treat more homogeneous groups of patients. This project will provide new knowledge about supra-threshold hearing abilities, such as loudness perception, binaural, spectral and temporal resolution in tinnitus patients that can help us gain a better understanding of the hearing deficits in the patients and how these are related to the tinnitus related distress. In fact, the vast majority of people suffering from tinnitus have a measurable hearing loss. However, hearing aid (HA) treatment is currently not successful for all tinnitus patients. These large individual differences with respect to the effect of HA treatment suggest a potential that more personalized HA fittings can lead to more successful tinnitus treatments. Here we propose that HA fittings can be personalized to tinnitus patients based on thorough examinations of patients’ hearing abilities. If successful, the knowledge obtained from this study could translate into more effective interventions for tinnitus patients, allowing more individualized and targeted treatments.
Axel Ahrens Assistant Professor Department of Health Technology aahr@dtu.dk
Speech communication challenges due to reverberation and hearing loss: Perceptual mechanisms and hearing-aid solutions
Hearing-impaired listeners are known to struggle to understand speech particularly in rooms with reverberation. The aim of this project is to understand the perceptual mechanisms of speech communication in listeners with hearing loss, particularly in the presence of reverberation. Furthermore, the influence of hearing aids and algorithms will be investigated.
Shixiang Yan PhD Student Department of Health Technology shiya@dtu.dk
Characterizing listener behavior in complex dynamic scenes
Shixiang’s project focuses on developing a comprehensive "behavioral profile" that characterizes how individuals listen and interact in real-world conversations. The underlying hypothesis is that difficulties in analyzing and processing complex scenes are reflected in specific behavioral features. The behavioral profile primarily encompasses three categories: acoustic-phonetic features, communication and interaction features, and motion features. The project will also investigate how the use of hearing aids and changes in acoustic scene complexity impact these behavioral profiles. Furthermore, it will explore the relationship between behavioral profiles and auditory profiles, offering insights into how hearing impairments are linked to communication behaviors.
The findings from Shixiang’s project will support the selection of appropriate "scene and profile-aware" compensation strategies tailored to the individual listener and environment. Additionally, the project may provide insights for advancing hearing rehabilitation techniques and diagnostic tools.
Cathrina Veigel PhD Student Department of Health Technology catve@dtu.dk
SPEECH INTELLIGIBILITY IN REALISTIC LISTENING ENVIRONMENTS
The aim of Cathrina’s PhD project is to investigate speech intelligibility in scenarios with varying degrees of realism to uncover challenges, cues and listening strategies in real-life situations. Contributions of different binaural cues, i.e. better ear listening (BE) and binaural unmasking (BU) will be analyzed across several naturally occurring dimensions, such as reverberation, number of talkers, and masker types.
Binaural (and monaural) auditory mechanisms and listening strategies that were observed in simplified listening scenarios (e.g. in anechoic situations, with only one interferer, noise interferer, etc.) may be relevant in the laboratory setting but not necessarily in real-life environments. It is still unclear how exactly these mechanisms (specifically BE and BU, but also other factors such as spatial release of informational masking) interact and contribute to speech intelligibility in realistic scenarios with more than one or two dimensions of realism, e.g. with multiple speech interferers and reverberation. This project will quantify and evaluate acoustic-scene realism as a multidimensional metric, simultaneously increasing the degree of complexity across these naturally occurring dimensions. The experimental data will be analyzed using auditory models proposing different binaural processing strategies. Additionally, current models will be enhanced based on the experimental findings to predict speech intelligibility in complex environments.
Quirin Mühlberger PhD Student Department of Health Technology qumu@dtu.dk
Individualization of Binaural Processing in Hearing Aid and Cochlear Implant Users
Understanding speech in environments with multiple spatially distributed noise sources and accurately localizing sounds in everyday life are significant challenges for users of hearing instruments, including both hearing aids (HAs) and cochlear implants (CIs). Binaural processing techniques, which integrate two HAs, two CIs, or one of each, aim to enhance the listening experience for these users. This project investigates which processing schemes are most suitable depending on the type of user. Additionally, it explores whether there are situation- and patient-specific preferences that influence the effectiveness of these techniques.
Cora Jirschik Caron Postdoc Department of Health Technology cjica@dtu.dk
Alina Schulte Postdoc Department of Health Technology aicue@dtu.dk
Assessing Listening-related Fatige in everyday life (ALFi)
Listening-related fatigue is a significant problem in hearing-aid users potentially predicting reduced well-being and social isolation. In collaboration with Eriksholm Research Center, the ALFi-project investigates how listening effort contributes to mental fatigue using a psychological computational model. We expect that listening effort causes fatigue to build up, affecting whether hearing aid users choose to engage or disengage in a listening situation. While effort-based decision models have been used in other domains, to date it remains unknown whether they also explain listening-effort induced mental fatigue states. Using pupillometry and fNIRS we are going to investigate neurophysiological markers of momentary changes in distinct fatigue states. In the long-term, the understanding of how biomarkers can predict momentary fatigue states would allow to adjust hearing settings on a momentary basis or allows tracking of listening battery to suggest resting phases.
Pernilla Kjær Andersen PhD Student Department of Health Technology pkjan@dtu.dk
Clinical Evidence for more Ecologically Valid Assessments of Hearing
Traditional audiological tests often fail to replicate real-world listening environments, leading to discrepancies between clinical assessments and patient experiences. This PhD project aims to develop and integrate novel, more ecologically valid assessments of hearing into clinical settings, addressing this critical gap in current diagnostic methodologies. We specifically want to employ our methods as pre-operative tools that can enhance clinical decision-making when working with cochlear implant (CI) recipients with single-sided deafness (SSD). Focusing on SSD patients is crucial because literature suggests that implantation in this population is valuable, yet clinical outcomes have been variable. These variations include differences in patient-reported outcomes, clinical test results, as well as the correlation between the two. Since the goal of implantation for SSD patients is to improve spatial hearing, applying more ecologically valid testing is essential to understand the impact on daily life. Conducting these assessments prospectively will help predict individual patient outcomes more accurately, thereby improving pre-operative counselling and candidate selection.
Collaboration
Hearing Systems participate in a number of national and international research project.
Assessment of Listening-related Fatigue in Daily-Life (ALFi) project
Conversing with family and friends is difficult for people with hearing loss. The brain has to compensate for the hearing loss and work harder in order to understand speech in busy environments of everyday life, and this is effortful, stressful, and tiring. While well-fitted hearing aids have been shown to improve speech intelligibility and reduce some of the physiological signs of listening effort, they do not necessarily reduce listening-related fatigue, which remains a significant problem for hearing-aid users.
The ALFi project proposes an innovative hybrid approach in which field and laboratory studies are initially run in parallel using a common experimental framework to determine behavioral and physiological measures sensitive to changes in listening-related stress and fatigue. This project will advance our understanding of listening fatigue as it occurs in the real world, develop a predictive model of the experience of fatigue states, and suggest ways to mitigate fatigue in hearing-aid users.
The project will be carried out in collaboration between Hearing Systems (Torsten Dau, Dorothea Wendt, Hamish Innes-Brown), Copenhagen University (Trine Flensborg-Madsen, Naja Hulvej Rod), University of Birmingham (Matthew Apps), Eriksholm Research Centre (Jeppe Høy Konvalinka Christensen, Dorothea Wendt, Hamish Innes-Brown, Ingrid Johnsrude) and University of Western Ontario (Ingrid Johnsrude) and has been supported by the William Demant Foundation.
Living and working in Denmark
Head of Section:
Torsten Dau Head of Sections, Professor Department of Health Technology Phone: +45 45253977 Mobile: 40 42 51 50 tdau@dtu.dk