
Teaching in courses:
We use digital signal processing and machine learning to analyze and process sound. Our main research focus is on the development of novel signal processing strategies that can improve the ability of hearing-impaired listeners to communicate in challenging acoustic environments. To achieve this, we combine digital signal processing and modern machine learning techniques with concepts from auditory signal processing and perception. We have a particular focus on complex acoustic scenes that resemble real-world listening situations.
Computational auditory scene analysis
The fascinating abilities of human listeners to analyze complex acoustic mixtures and to focus on a particular target source is referred to as auditory scene analysis (ASA). The research field of computational auditory scene analysis (CASA) aims at building computational models that can replicate aspects of ASA with machines.
One important task of CASA is to determine the spatial location of sound sources. Human listeners are remarkably good at localizing sounds, even in adverse acoustic conditions where competing talkers and room reverberation are present. The main cues that are exploited by the auditory system are interaural time and level differences (ITDs and ILDs). When considering the task of localizing sound sources in the full horizontal plane (360 degree), a machine hearing system based on ITDs and ILDs is likely to produce a substantial amount of front-back errors given the similarities of ITDs and ILDs in the front and the rear hemifield. To overcome this limitation and to increase the robustness of sound source localization in adverse acoustic conditions, the machine hearing system can be extended to exploit head movements.
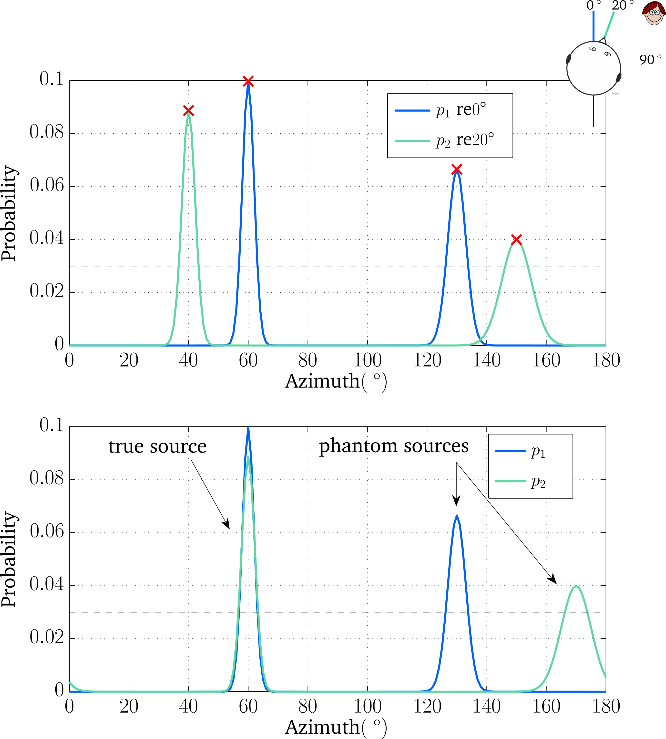
Figure 1 The benefit of head rotation in a machine hearing system. The upper panel shows the azimuth probability distribution of a localization model for two different head orientations. After compensating for the head rotation, the azimuth candidates corresponding to the true source location align in the lower panel and can thus be distinguished from phantom sources.
The benefit of head movements is illustrated in Figure 1. A localization model can be used to produce azimuth probability distributions for two different head orientations, e.g. relative to 0 and 20 degree as shown by the blue and the green line in the upper panel of Figure 1. Both azimuth probability distributions contain two azimuth candidates, as indicated by the red crosses. When rotating the head from 0 to 20 degree, the azimuth candidate that corresponds to the true source location will systematically shift towards the opposite direction of the head rotation. When compensating for the azimuth shift induced by the head rotation, the azimuth candidates that reflect the true source location will align, as shown in the lower panel of Figure 1. In contrast, phantom peaks will occur at different azimuth angles and can thus be removed.
This head movement strategy was shown to substantially reduce the amount of front-back confusions in challenging acoustic scenarios. An interesting direction for future investigations is to consider natural head movements of human listeners inside such a computational machine hearing system.
Selected publications:
- Ma, N., May, T. and Brown, G. J. (2017), "Exploiting deep neural networks and head movements for robust binaural localization of multiple sources in reverberant environments," IEEE/ACM Transactions on Audio, Speech, and Language Processing 25(12), pp. 2444-2453.
- May, T, Ma, N., and Brown, G. J. (2015), "Robust localisation of multiple speakers exploiting head movements and multi-conditional training of binaural cues," in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 2679-2683.
- Ma, N., May, T., Wierstorf, H., and Brown, G. J. (2015), "A machine-hearing system exploiting head movements for binaural sound localisation in reverberant conditions," in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 2699-2703.
- May, T., van de Par, S., and Kohlrausch, A. (2013), “Binaural localization and detection of speakers in complex acoustic scenes,” in The Technology of Binaural Listening, J. Blauert, Ed.,Berlin–Heidelberg–New York NY: Springer, 2013, ch. 15, pp. 397–425.
- May, T., van de Par, S., and Kohlrausch, A. (2011), “A probabilistic model for robust localization based on a binaural auditory front-end,” IEEE Transactions on Audio, Speech, and Language Processing 19(1), pp. 1–13.
Speech enhancement
A major challenge of hearing-impaired listeners is to focus on a specific target source in noisy and reverberant environments. Thus, the development of technical solutions that can improve the quality and intelligibility of noisy and reverberant speech is of fundamental importance for a wide range of application, such as mobile communication systems and hearing aids.
A promising approach is to use machine learning to establish a systematic mapping between a set of features that can be extracted from the noisy speech mixture and the underlying short-term signal-to-noise ratio that can be calculated by using a priori knowledge about the individual speech and noise signals during the training stage. Such a deep neural network (DNN)-based speech enhancement system is shown in Figure 2.
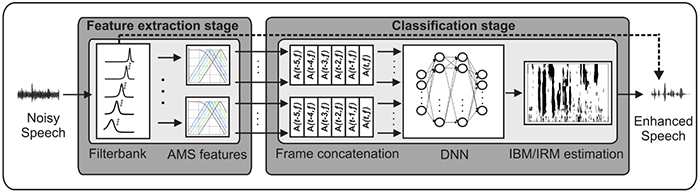
Figure 2 A deep neural network (DNN)-based speech enhancement system. Given a noisy speech mixture, a set of auditory-inspired features is extracted for individual frequency bands. A pre-trained DNN is then used to estimate a time-varying gain function that can be applied to the individual frequency bands of the noisy mixture to enhance the target.
The DNN-based speech enhancement system was shown to improve speech intelligibility in adverse condition where speech was corrupted by a six-talker babble noise at low signal-to-noise ratios. Future research will focus on improving the generalization abilities of learning-based techniques to realistic acoustic conditions not seen during the training stage.
Selected publications:
- Bentsen, T., May, T., Kressner, A. A. and Dau, T. (2018), “The benefit of combining a deep neural network architecture with ideal ratio mask estimation in computational speech segregation to improve speech intelligibility,” PLoS One 13(5), pp. 1–13.
- Bentsen, T., Kressner, A. A., Dau, T. and May, T. (2018), “The impact of exploiting spectro-temporal context in computational speech segregation,” Journal of the Acoustical Society of America 143(1), pp. 248–259.
- May, T. (2018), “Robust speech dereverberation with a neural network-based post-filter that exploits multi-conditional training of binaural cues,” IEEE/ACM Transactions on Audio, Speech, and Language Processing 26(2), pp. 406–414.
- May, T. and Dau, T. (2014), “Computational speech segregation based on an auditory-inspired modulation analysis,” Journal of the Acoustical Society of America 136(6), pp. 3350–3359.
- May, T. and Dau, T. (2014), “Requirements for the evaluation of computational speech segregation systems,” Journal of the Acoustical Society of America 136(6), pp. EL398–EL404
Hearing aid compensation strategies
Wide dynamic range compression (WDRC) is one of the essential building blocks in hearing aids and aims at restoring audibility for hearing-impaired listeners while maintaining acceptable loudness at high sound pressure levels. This can be achieved by providing level-dependent amplification. While fast-acting compression with a short release time allows amplifying low-intensity speech sounds on short time scales corresponding to syllables or phonemes, such processing also typically amplies noise components and reverberant energy in speech gaps. Some of these shortcomings can be avoided by using a longer release time, but such a slow-acting compression system fails to amplify soft speech components on short time scales and compromises on the ability to restore loudness perception.
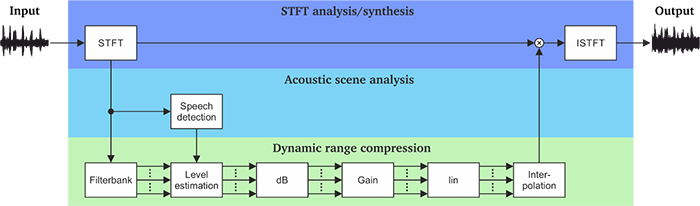
Figure 3 Scene-aware dynamic range compression system consisting of three layers: (1) analysis and synthesis stage based on the short-time discrete Fourier transform, (2) short-term speech detection, and (3) dynamic range compression. The estimated speech activity in individual time-frequency units is used to adjust the release time constant in the level estimation stage. Specifically, time-frequency units with speech activity are processed with fast-acting compression, while slow-acting compression is applied to time-frequency units that are dominated by background noise or reverberation.
To overcome this, a new scene-aware dynamic range compression strategy was developed which attempts to combine the advantages of both fast- and slow-acting compression. As shown in Figure 3, the scene-aware dynamic range compression system has a dedicated acoustic scene analysis layer that detects speech activity in individual time-frequency units. The subsequent level estimation stage adapts the release time constant in individual time-frequency units to provide either fast- or slow-acting compression depending on whether the target speech was active or absent.
This new scene-aware dynamic range compression system was shown to provide a speech intelligibility benefit over slow-acting compression while preserving the listener’s spatial impression.
Selected publications:
- May, T., Kowalewski, B. and Dau, T. (2020), “Scene-aware compensation strategies for hearing-aids,” in The Technology of Binaural Understanding, J. Blauert and J. Braasch, Ed., Berlin–Heidelberg–New York NY: Springer, 2020, ch. 25.
- Kowalewski, B., Dau, T. and May, T. (2020), “Perceptual evaluation of signal-to-noise-ratio-aware dynamic range compression in hearing aids,” Trends in Hearing 24, pp. 1–14.
- Kowalewski, B., Zaar, J., Fereczkowski, M., MacDonald, E. N., Strelcyk, O., May, T., and Dau, T. (2018), “Effects of slow- and fast-acting compression on hearing-impaired listeners’ consonant–vowel identification in interrupted noise,” Trends in Hearing 22, pp. 1–12.
- May, T., Kowalewski, B. and Dau, T. (2018), “Signal-to-noise-ratio-aware dynamic range compression in hearing aids,” Trends in Hearing 22, pp. 1–12.
- Hassager, H. G., May, T., Wiinberg, A. and Dau, T. (2017), “Preserving spatial perception in rooms using direct-sound driven dynamic range compression,” Journal of the Acoustical Society of America 141(6), pp. 4556–4566.